Dades enllaçades, el futur de les biblioteques
Les biblioteques proporcionen accés als seus fons mitjançant l'ús de l’OPAC, un component fonamental dels sistemes integrats de biblioteques que facilita l'accés als usuaris a la informació (dades bibliogràfiques i d'autoritat) emmagatzemada en format MARC. Tanmateix tot i que els catàlegs de les biblioteques estan presents al web, hem de ser conscients que no participen del web semàntic, les dades que proporcionem no es relacionen ni interactuen amb altres dades i no poden ser explotades pels motors de cerca i altres aplicacions.
En aquests moments, la informació que es troba en els catàlegs és llegible i comprensible per als humans, però no està optimitzada per a la comprensió dels ordinadors. La solució a aquest problema és l’ús de dades enllaçades (en anglès Linked Data o Linked Open Data si parlem d’un format obert sense cap restricció). Un exemple clar del seu potencial és el gràfic de coneixement de Google (Knowledge Graph), una base de dades que proporciona informació pertinent a una cerca a partir de dades semànticament rellevants procedents de Wikipedia, Wikidata, CIA World Factbook, Freebase, etc. Amb aquesta eina el cercador ja no es limita a cercar una cadena de caràcters coincidents, sinó que arriba a “entendre” el que s’està cercant.
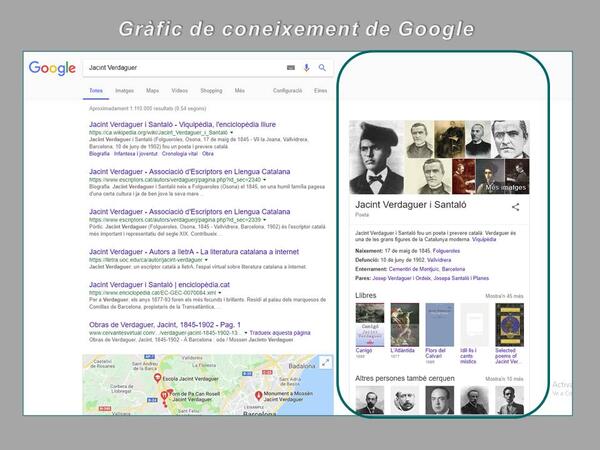
Captura de la cerca de “Jacint Verdaguer” per Google (11-04-2018)
Quan les biblioteques utilitzin les dades enllaçades per presentar els seus fons al web, es podrà fer ús d’eines similars que permetran que moltes persones no usuàries de les biblioteques trobin informació més pertinent del llibre o del recurs que busquen i de la seva disponibilitat a la biblioteca més propera. Les dades que proporcionem els catalogadors poden ser increïblement útils com a part de la remescla (mashup en anglès) de dades del web, ja que són dades de qualitat i esdevindran més fàcils de trobar i relacionar per un cercador.
Amb l’aplicació d’RDA a la catalogació, que ens permet proporcionar metadades fiables, amb el llenguatge XML i l’ús de les tecnologies del web semàntic, tenim la possibilitat de tractar la informació com a dades enllaçades, de tal manera que puguin ser enteses pels ordinadors i compartides amb altres productors o gestors d’informació, la qual cosa repercutirà sens dubte en la reducció dels costos de catalogació i, en definitiva, al millorament dels servei als usuaris.
Què són les dades enllaçades?
Les dades enllaçades es defineixen com un conjunt de bones pràctiques necessàries per a la publicació i la connexió de dades que s'estructuren de manera que les màquines puguin utilitzar-les i relacionar-les. En essència, es tracta de codificar les dades amb significat semàntic perquè puguin ser utilitzades pels ordinadors.

Tim Berners-Lee. Linked Data—Design Issues (W3C, 27-07-2006)
Les dades enllaçades no són un estàndard o un protocol en si mateix, sinó l'ús de diversos estàndards que proporcionen el significat necessari perquè els ordinadors puguin gestionar les dades:
1. Cal una direcció única (Uniform Resource Identifier, URI), que identifiqui el tipus d’objecte o concepte.
2. Cal posar les dades en línia (HTTP) per poder-les consultar i vincular.
3. Cal que es proporcionin dades útils, fent ús d'estàndards com RDF o SPARQL.
4. Les dades s’han d’enllaçar amb altres dades en el web mitjançant el corresponent URI.
Un dels estàndards que s'utilitzen habitualment en projectes de dades enllaçades és l’RDF. Aquest estàndard permet descriure recursos web, és a dir, qualsevol cosa que pugui ser recuperada i identificada amb un URI (o per un Internationalized Resource Identifier, IRI). Les descripcions RDF es basen en una simple expressió anomenada tripleta, que consisteix en relacionar un subjecte i un objecte mitjançant un predicat. Per exemple, una expressió com “Jacint Verdaguer és autor de Canigó”, en RDF “Jacint Verdaguer” correspondria al subjecte i “Canigó” a l’objecte, ambdós relacionats pel predicat “és autor de”.
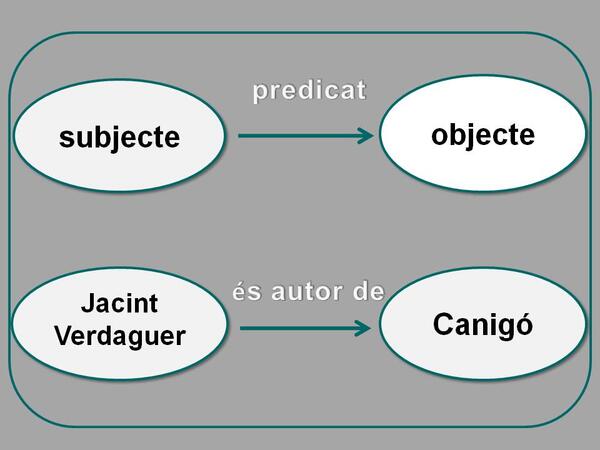
Representació “Jacint Verdaguer és autor de Canigó”, en RDF
Perquè les màquines puguin entendre aquesta expressió és necessari que el subjecte es defineixi amb un URI (o per un node en blanc quan no coneixem l’URI), el predicat sempre ha d’estar definit per un URI, i l’objecte pot estar definit per un URI, un literal o un node en blanc.
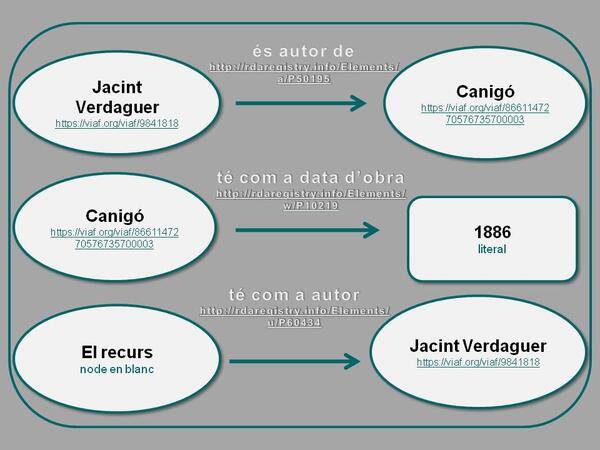
Representació de tipus de tripletes en RDF
Les tripletes es poden enllaçar entre si conformant el que s’anomena un graf.
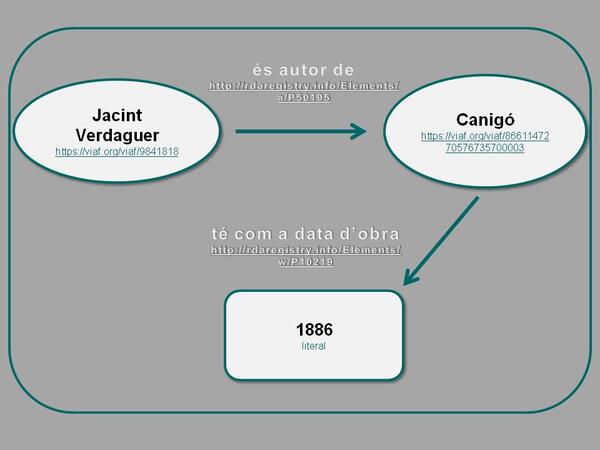
Representació del graf “Jacint Verdaguer és autor de Canigó de 1886” en RDF
Per expressar un o més grafs RDF en un fitxer llegible per màquines s’utilitzen formats de serialització com poden ser RDF/XML, N-Triples, Turtle, JSON-LD, etc.
És important que tots els URIs d'un mateix vocabulari comencin amb una mateixa subcadena de caràcters, anomenada espai de noms (namespace en anglès), que normalment està identificada per un nom curt o prefix.
Hi ha molts vocabularis disponibles en format RDF, entre ells RDA.

Turtle del graf “Jacint Verdaguer és autor de Canigó de 1886”
Les dades enllaçades són aplicables a les biblioteques?
Les dades dels milions de registres bibliogràfics i d’autoritat dels catàlegs es poden convertir en dades enllaçades a partir d’estàndards com RDF. És cert que hi ha molta feina a fer, però ja s'està treballant perquè això sigui possible.
Tot i que RDA va començar com un manual d'instruccions (un "estàndard de contingut") destinat a la creació de descripcions bibliogràfiques, els seus vocabularis i valors estan registrats a RDA Registry, una infraestructura per a aplicacions de dades RDA, basada en l’Open Metadata Registry (OMR). Les entitats han estat representades en RDF com a classes i els atributs i les relacions com a propietats (o predicats) i s’han creat identificadors específics per a cada element.
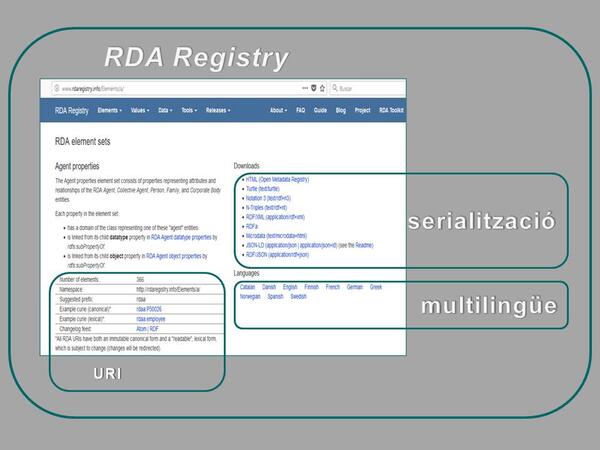
Captura d’RDA Registry (11-04-2018)
També s’està treballant en URIs per a les autoritats creades per les biblioteques, com fan per exemple la Library of Congress a través del LC Linked Data Service: Authorities and Vocabularies o projectes internacionals com el VIAF (Virtual International Authority File).
El 2011, la Library of Congress va contractar l’empresa Zepheira per iniciar el procés per traslladar les dades de la biblioteca al web. El primer objectiu ha estat definir un model de dades enllaçades anomenat BIBFRAME (el substitut del format MARC). Actualment les especificacions al mapatge ja estan disponibles i el programa de conversió es troba disponible per ser descarregat al lloc Github.
Zepheira, mitjançant el projecte col·laboratiu Libhub Initiative, va començar a treballar per transformar els registres bibliogràfics MARC a dades enllaçades. Tanmateix el gran repte no és només carregar les dades d'una biblioteca al web, fet que no tindria cap impacte, sinó enllaçar els recursos amb les biblioteques perquè els usuaris puguin descobrir aquests recursos al web i redirigir-los al catàleg. El primer resultat ha estat Library.Link Network.
Actualment cal destacar també Linked Data for Libraries (LD4L), una iniciativa dedicada a explorar el potencial de les dades enllaçades per a biblioteques.
A nivell europeu, un dels primers exemples d'ús de dades enllaçades a les biblioteques és el catàleg col·lectiu suec LIBRIS, que va començar a compartir dades enllaçades el 2008. Altres biblioteques que utilitzen dades enllaçades són la British Library per a la British National Bibliography i la Open Library. Les biblioteques alemanyes també fa temps que hi treballen: el primer servei de dades obertes enllaçades de la Deutsche Nationalbibliothek va ser per a les autoritats de noms i de matèries, posteriorment va implementar un prototip de BIBFRAME a l’OPAC. També és interessant la Nordrhein-Westfälische Bibliographie (NWBib), amb l’aplicació tecnològica pròpia dels motors de cerca per a la millora del temps de resposta. La Bibliothèque nationale de France també ha desenvolupat el projecte data.bnf.fr, molt atractiu de cara a l’usuari, que recopila en un únic repositori la informació procedent dels seus catàlegs així com de la seva biblioteca digital Gallica. La Biblioteca Nacional de España té així mateix un interessant projecte experimental conegut com datos.bne.es, sumant-se al repte de publicar els catàlegs bibliogràfics i d'autoritats en format RDF.
Per acabar, només apuntar que hi ha empreses i proveïdors de sistemes treballant per oferir a les biblioteques noves eines que s’ajustin a les noves necessitats. Trobem OCLC, que des de fa temps treballa estretament amb altres organitzacions, com la Library of Congress, el W3C i altres grups i iniciatives de dades enllaçades, assegurant que les dades de WorldCat s'incloguin al web. Un altre exemple és Casalini Libri, en col·laboració amb @Cult, creadors d’un prototip per a la visualització de dades anomenat SHARE-VDE (SHARE Virtual Discovery Environment) basat en una arquitectura BIBFRAME. L’empresa Ex Libris i l’ELUNA/IGeLU Linked Open Data Special Interest Working Group s’han centrat especialment en un conversor de MARC a BIBFRAME i en la edició de dades mitjançant la plataforma de serveis ALMA; tenen previst que els clients puguin produir dades enllaçades amb una eina de catalogació. Per últim, Zepheira, empresa de consultoria de dades enllaçades vinculada a diverses iniciatives, també ha estat treballant amb proveïdors com EBSCO, Atlas Systems, Innovative i SirsiDynix.
Imma Ferran
Servei de Normalització Bibliogràfica
Facebook de la biblioteca Twitter de la biblioteca Flickr de la biblioteca Tagpacker de la biblioteca Canal Youtube de la biblioteca Pinterest de la biblioteca Instagram de la biblioteca